
CRISPRMED24 Testimonial - Laura...
Jan. 21, 2025


CMN Intelligence - The World’s Most Comprehensive Intelligence Platform for CRISPR-Genomic Medicine and Gene-Editing Clinical Development
Providing market intelligence, data infrastructure, analytics, and reporting services for the global gene-editing sector. Read more...
Hello and welcome back to another instalment of Making the Cut, the weekly (or at least we try!) series where we tell you all the juicy secrets behind the most exciting gene editing technologies!
After telling you how Prime Editing works and how it can be used to cure diseases, last week we finished our 3-episode marathon on prime editing by delving into the world of recombinases, and how their combination with prime editing allows us to perform large DNA integrations without double-strand breaks (DSBs). If you missed any of that, go check it out! We’ll patiently wait for you to catch up.
Now, we know you must be thinking that his really has to be CRISPR’s final evolution. But we wouldn’t be here if it was, would we? Indeed, this week we bring you a very novel (literally 5 months old!) technology that promises to give prime editing a run for its money.
So join us as we introduce you to click editing, the newest, most fancy-named gene editing technology, and how cool it is!
We know, after our three last episodes we had you completely convinced that this was it: prime editing was the one and only, capable of everything and we should all bow to it. While that is mostly true (prime editing does, indeed, kick ass), there are always things that we can improve. We know, you’re dreading that we’re going to go back into the nightmare of DNA-protein interactions underlying prime editing. Relax, we’re keeping those where they belong, on episode 16!
So, what are we talking about here? How can we improve prime editing? It turns out that, while we described prime editing to you as a sure thing, it is not always very efficient. That is because, depending of the target DNA region and the desired insert, the pegRNA (the prime editing RNA molecule that includes the gRNA and the template for the insert) may not be ideal to achieve a high integration efficiency. This efficiency depends on various characteristics of the pegRNA, including the length of the primer binding site, the length of the integration template and more.
Luckily, these are parameters that we can change to optimize our pegRNA. However, we don’t yet have good models to predict pegRNA efficiency, which means that we need to test multiple pegRNA variations in order to find the perfect one.

So that’s it? Just a matter of trial and error? Doesn’t sound like a big deal, right? Well, what if we told you that it takes about a week, at least, to get every pegRNA ready to test? Not only that, but making long RNA molecules (which pegRNAs are) comes with its own set of problems we haven’t discussed yet, the biggest one being their price.
So, imagine that to optimize a prime editing approach, you need to design, produce and test 100-200 pegRNAs. That would take plenty of time, and a good amount of money
What can we do to improve that process? The answer is getting rid of the pegRNA altogether!
We know what you must be thinking: isn’t the pegRNA what makes prime editing…well, prime editing? And you are absolutely right. However, if you think about it, the insert we want to produce will be DNA, so why do we use RNA to code for it? The simple answer is that, for prime editing to work, we need all of the main players (that is Cas9, the reverse transcriptase (RT) and the template) to be right next to each other at the target site right at the precise moment. For this reason, the elegant design of the pegRNA, which binds the template to Cas9, is very useful.
However, what if there was a way of bringing a single-stranded DNA (ssDNA) template as close, or closer, to the target site? ssDNA is, in the end, way simpler and cheaper to produce than RNA. Additionally, since our ssDNA would encode only for the insertion template, it would be significantly shorter than a pegRNA, making it faster to have ready.
Okay, so ssDNA has its merits, but is there a way to bind a ssDNA to the editing complex to achieve the same result? You may be surprised to learn that there were two different research groups that asked themselves the exact same question. The funniest part? They were only 68km away from each other!

Indeed, the groups of Ben Kleinstiver Kleinstiver at MGH & Harvard Medical School and Eric Sontheimer at the RNA Therapeutics Institute at UMass Chan Medical School had the same idea, although they approached it in slightly different ways. For simplicity and length, today we will look at the Kleinstiver’s group’s approach, called click editing. But if you want to learn more about the other approach, check out this article on CRISPR Medicine News by our own Manel Lladó!
Okay, so back to the gist of it. First of all, to use a ssDNA template, the researchers needed to replace the RT in the prime editing complex with an enzyme capable to read and write a DNA sequence. Thankfully, our cells have plenty of those enzymes, called DNA-dependent DNA polymerases (DDPs). Moreover, DDPs provide significant advantages over RTs, because they’re not only faster and more precise, but they also come from our own cells. This means that we don’t have to worry about our cells rejecting them and treating them as pathogenic proteins, which was a concern with RTs that, as you may remember, are derived from viruses.
Okay, so we replaced RT with a DDP and made a new type of editing complex, which we will call a click editor. Now what? How do we attach the DNA template to the click editor to make sure our edit occurs? The answer is (don’t kill us, it’s not our fault), an extra protein.

An extra protein? Don’t we have enough with Cas9 and the DDP? Do we always have to make it more complicated? Okay, we get your point, but we promise that this one is a really, really tiny protein. So small you won’t even notice it. Actually, it’s not even a full protein, just a piece of it.
The protein is called an HUH endonuclease, and its function is to break apart ssDNA molecules. But wait, don’t get alarmed yet! We’re obviously not breaking apart our ssDNA template. The team of Ben Kleinstiver realized that they could isolate a domain of this HUH endonuclease that is responsible for binding a specific ssDNA sequence, which they could add to their ssDNA. Then they attached this little part of the protein to their editing complex. That is like sticking a lego board to your wall so that you can hang your keys by their lego-shaped keychain. Easy, resistant and functional! Not to mention, classy!
Indeed, attaching the DNA-binding domain of the HUH endonuclease to the DDP allowed the Kleinstiver team to easily “click in” any dsDNA template. And voilà, “Click” Editing. Get it? We know, we know. Still, this new approach allowed the team to achieve similar integration efficiency as when using conventional prime editing. Not too bad, is it?
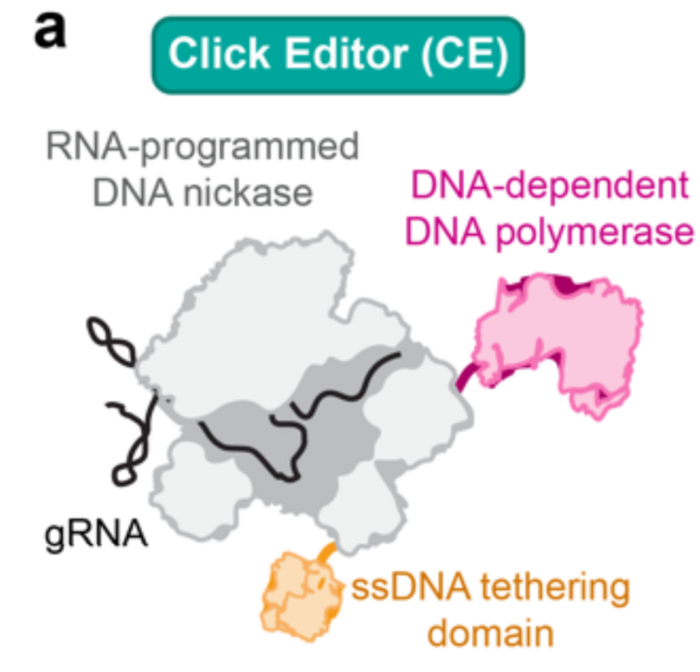
Of course, this approach is still at its embryonic stages and will, hopefully, be significantly improved when it comes to efficiency. However, click editing is already proving to be a fair competitor to prime editing, and allowing easier and cheaper template optimization that will hopefully lead to new discoveries!
With this, we’ve reached the end of this week’s instalment of Making the Cut! If you’re left wanting more, check out our previous episodes (we know some of you didn’t read them all).
Next week, we’ll move on to a different CRISPR-based technology that does not alter the DNA sequence at all, epigenome editing! Don’t miss it!
To get more CRISPR Medicine News delivered to your inbox, sign up to the free weekly CMN Newsletter here.





